Maneja-dores de bases de datos:
Oracle Database: es un sistema de gestión de base de datos objeto-relacional (u ORDBMS por el acrónimo en inglés de Object-Relational Data Base Management System), desarrollado por Oracle Corporation. Se considera a Oracle Database como uno de los sistemas de bases de datos más completos, destacando:
- soporte de transacciones.
- estabilidad.
- escalabilidad.
- soporte multiplataforma.
Su dominio en el mercado de servidores empresariales ha sido casi total hasta hace poco; recientemente sufre la competencia del Microsoft SQL Server de Microsoft y de la oferta de otros RDBMS con licencia libre como PostgreSQL, MySQL o Firebird. Las últimas versiones de Oracle han sido certificadas para poder trabajar bajo GNU/Linux.
Sybase IQ: es un motor de bases de datos altamente optimizado para inteligencia empresarial, desarrollado por la empresa Sybase,
llamado ahora Sap Sybase IQ debido a la compra de la empresa Sybase por
parte de Sap. Diseñado específicamente para entregar resultados más
rápidos en soluciones de inteligencia empresarial analítica de misión
crítica, almacenes de datos
y generación de reportes, Sybase IQ combina velocidad y agilidad, con
un bajo costo total de propiedad, lo que permite a las empresas llevar a
cabo análisis de datos y generación de reportes antes impensables,
imprácticos o costosos. La más reciente versión de SAP Sybase IQ es la
16.

Firebird sql: es un sistema de administracion de base de datos relacional (o RDBS) (Lenguaje consultas: SQL) de codigo abierto, basado en la versión 6 de interfase, cuyo código fue liberado por Borland en 2000. Su código fue reescrito de C a C++ El proyecto se desarrolla activamente, el 18 de abril del 2008 fue liberada la versión 2.1 y el 26 de diciembre del 2009 fue liberada la versión 2.5.0 RC1. La versión 2.5.2, la más reciente del proyecto, fue liberada el 24 de marzo de 2013
- Es multiplataformas, y actualmente puede ejecutarse en los sistemas operativos: Linux, Hp-Ux, FreeBSD, Mac OS, Solaris y Microsoft Windows. ,
- Ejecutable pequeño, con requerimientos de hardware bajos.
- Arquitectura Cliente/Servidor sobre protocolo TPC/IP y otros (embedded).
- Soporte de transacciones ACID y claves foraneas.
- Es medianamente escalable.
- Buena seguridad basada en usuarios/roles.
- Diferentes arquitecturas, entre ellas el Servidor Embebido (embedded server) que permite ejecutar aplicaciones monousuario en ordenadores sin instalar el software Firebird.
- Bases de datos de sólo lectura, para aplicaciones que corran desde dispositivos sin capacidad de escritura, como cd-roms.
- Existencia de controladores OBDC, OLEDB, JDBC, PHP, PERL, .net, etc.
- Requisitos de administración bajos, siendo considerada como una base
de datos libre de mantenimiento, al margen de la realización de copias
de seguridad.
- Pleno soporte del estándar SQL-97, tanto de sintaxis como de tipos de datos.
- Completo lenguaje para la escritura de disparadores y procedimientos almacenados denominado PSQL.
- Capacidad de almacenar elementos BLOB (Binary Large OBjects).
- Soporte de User-Defined Functions (UDFs).
- Versión autoejecutable, sin instalación, excelente para la creación
de catálogos en CD-Rom y para crear versiones de evaluación de algunas
aplicaciones.
 PostgreSQL:
PostgreSQL: es un SGBD relacional orientado a objetos y libre, publicado bajo la licencia BSD. Como muchos otros proyectos de código abierto, el desarrollo de PostgreSQL no es manejado por una empresa y/o persona, sino que es dirigido por una comunidad de desarrolladores que trabajan de forma desinteresada, altruista, libre y/o apoyados por organizaciones comerciales. Dicha comunidad es denominada el PGDG (PostgreSQL Global Development Group).
Algunas de sus principales características son, entre otras:
Alta concurrencia
Mediante un sistema denominado MVCC (Acceso concurrente multiversión, por sus siglas en inglés) PostgreSQL permite que mientras un proceso escribe en una tabla, otros accedan a la misma tabla sin necesidad de bloqueos. Cada usuario obtiene una visión consistente de lo último a lo que se le hizo commit. Esta estrategia es superior al uso de bloqueos por tabla o por filas común en otras bases, eliminando la necesidad del uso de bloqueos explícitos...
Amplia variedad de tipos nativos
PostgreSQL provee nativamente soporte para:
Números de precisión arbitraria.
Texto de largo ilimitado.
Figuras geométricas (con una variedad de funciones asociadas).
Direcciones IP (IPv4 e IPv6).
Bloques de direcciones estilo CIDR.
Direcciones MAC.
Arrays.
Adicionalmente los usuarios pueden crear sus propios tipos de datos, los que pueden ser por completo indexables gracias a la infraestructura GiST de PostgreSQL. Algunos ejemplos son los tipos de datos GIS creados por el proyecto PostGIS.
 Interbase:
Interbase: es un sistema de gestión de bases de datos relacionales (RDBMS) desarrollado y comercializado por la compañía Borland Software Corporation y actualmente desarrollado por su ex-filial CodeGear. Interbase se destaca de otros DBMS's por su bajo consumo de recursos, su casi nula necesidad de administración y su arquitectura multi-generacional. InterBase corre en plataformas Linux, Microsoft Windows y Solaris. Normalmente los servidores InterBase no requieren administradores de bases de datos a tiempo completo.
El control de concurrencia: Considere la posibilidad de una simple aplicación bancaria en la que dos usuarios tienen acceso a los fondos en una cuenta particular. Bob lee la cuenta y encuentra que hay 1.000 dólares en ella, por lo que retira 500. Jane utiliza la misma cuenta pero antes de que Bob haya aplicado los cambios, considera que hay 1000 dólares y retira 800. La cuenta debería tener 300 dólares en descubierto, sin embargo (asumiendo que no puede haber descubierto) dependiendo de la transacción que se procese primero, tendrá 500 ó 200 dólares. Esto plantea un grave problema ante el cual cualquier sistema de bases de datos con acceso multiusuario debe responder ofreciendo un sistema con el que gestionar estas situaciones.
 Microsoft SQL Server
Microsoft SQL Server es un sistema para la gestión de bases de datos producido por Microsoft basado en el modelo relacional. Sus lenguajes para consultas son T-SQL y ANSI SQL. Microsoft SQL Server constituye la alternativa de Microsoft a otros potentes sistemas gestores de bases de datos como son Oracle, PostgreSQL o MySQL.
- Soporte de transacciones.
- Soporta procedimientos almacenados.
- Incluye también un entorno gráfico de administración, que permite el uso de comandos DDL y DML gráficamente.
- Permite trabajar en modo cliente-servidor, donde la información y datos se alojan en el servidor y los terminales o clientes de la red sólo acceden a la información.
- Además permite administrar información de otros servidores de datos.
Este sistema incluye una versión reducida, llamada MSDE con el mismo motor de base de datos pero orientado a proyectos más pequeños, que en sus versiones 2005 y 2008 pasa a ser el SQL Express Edition, que se distribuye en forma gratuita.
Es común desarrollar completos proyectos complementando Microsoft SQL Server y Microsoft Access a través de los llamados ADP (Access Data Project). De esta forma se completa la base de datos (Microsoft SQL Server), con el entorno de desarrollo (VBA Access), a través de la implementación de aplicaciones de dos capas mediante el uso de formularios Windows.
En el manejo de SQL mediante líneas de comando se utiliza el SQLCMD, osql, o PowerShell.
Para el desarrollo de aplicaciones más complejas (tres o más capas), Microsoft SQL Server incluye interfaces de acceso para varias plataformas de desarrollo, entre ellas .NET, pero el servidor sólo está disponible para Sistemas Operativos.
El tipo NUMERIC fue mejorado para ser usado como identificador de columna a partir de la versión 2008 R2
 Terminologia:
Campo
Terminologia:
Campo: Un campo es cada uno de los tipos de datos que se van a usar. Se hace referencia a los campos por su nombre.
Registro: Un registro está formado por el conjunto de información en particular.
Dato: Un dato es la intersección entre un campo y un registro.
Tablas: Una tabla de una base de datos es similar en apariencia a una hoja de cálculo, en cuanto a que los datos se almacenan en filas y columnas. Como consecuencia, normalmente es bastante fácil importar una hoja de cálculo en una tabla de una base de datos. La principal diferencia entre almacenar los datos en una hoja de cálculo y hacerlo en una base de datos es la forma de organizarse los datos.
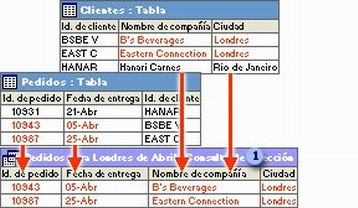
 Consultas:
Consultas: Las consultas son las que verdaderamente hacen el trabajo en una base de datos. Pueden realizar numerosas funciones diferentes. Su función más común es recuperar datos específicos de las tablas. Los datos que desea ver suelen estar distribuidos por varias tablas y, gracias a las consultas, puede verlos en una sola hoja de datos. Además, puesto que normalmente
 Formularios:
Formularios: Los formularios se conocen a veces como "pantallas de entrada de datos". Son las interfaces que se utilizan para trabajar con los datos y, a menudo, contienen botones de comando que ejecutan diversos comandos. Se puede crear una base de datos sin usar formularios, editando los datos de las hojas de las tablas. No obstante, casi todos los usuarios de bases de datos prefieren usar formularios para ver, escribir y editar datos en las tablas.
 Páginas de acceso a datos
Páginas de acceso a datos: Una página de acceso a datos es una página Web que se puede utilizar para agregar, modificar, ver o manipular datos actuales en una base de datos de Microsoft Access o de SQL Server. Se pueden crear páginas que se utilizarán para especificar y modificar datos, de manera similar a los formularios de Access. También se pueden crear páginas que muestren registros agrupados jerárquicamente, de manera similar a los informes de Acces.
 Tipos de datos:
CARACTERES
Tipos de datos:
CARACTERES
El tipo de dato carácter es un dígito individual el cual se puede representar como numéricos (0 al 9), letras (a-z) y símbolo ($,_). NOTA: En lenguaje java la codificación Unicode permite trabajar con todos los caracteres de distintos idiomas.
Tipo de dato Rango Tamaño de bits
char 0 a 65535 16 bits
El tipo integer (entero)
Como ya habrás leído el tipo de datos entero es un tipo simple, y dentro de
estos, es ordinal. Al declara una variable de tipo entero,
estás creando una variable numérica que puede tomar valores positivos o
negativos, y sin parte decimal.
Este tipo de variables, puedes utilizarlas en asignaciones, comparaciones, expresiones
aritméticas, etc. Algunos de los papeles más comunes que desarrollan
son:
- Controlar un bucle
- Usarlas como contador, incrementando su valor cuando sucede algo
- Realizar operaciones enteras, es decir, sin parte decimal
- Y muchas más...
type
tContador = integer;
var
i : tContador;
n : integer;
begin
n := 10; (* asignamos valor al maximo *)
i := 1; (* asignamos valor al contador *)
while (i <= n) do begin
writeln('El valor de i es ',i);
i := i + 1
end
end.
NUMÉRICOS
Este tipo de dato puede ser real o entero, dependiendo del tipo de dato que se vaya a utilizar.
Enteros:
son los valores que no tienen punto decimal, pueden ser positivos o negativos y el cero.
tipo de dato: byte tamaño= 8 bits
tipo de dato: short tamaño= 16 bits
tipo de dato: int tamaño= 32 bits
tipo de dato: long tamaño= 64 bits
Los tipos char y string (carácter y cadena)
Con el tipo carácter puedes tener objetos que representen una letra, un número,
etc. Es decir, puedes usar variables o constantes que representen un valor
alfanumérico. Pero ojo, cada variable sólo podrá almacenar un carácter.
Sin embargo, con las cadenas de caracteres (strings) puedes contener en una sóla
variable más de un carácter.
type
tNombre = string[10]; (* puede almacenar 10 caracteres *)
var
nombre : tNombre; (* variable para almacenar el nombre *)
letra_NIF : char; (* caracter para contener la letra del NIF *)
begin
nombre := 'Beni';
letra_NIF := 'L';
writeln('Mi nombre es ',nombre,' y mi letra es ',letra_NIF)
end.
Reales:
estos caracteres almacenan números muy grandes que poseen parte entera y parte decimal.
tipo de dato: float= 32 bits
tipo de dato: double= 64 bits
BOOLEANOS
Este tipo de dato se emplea para valores lógicos, los podemos definir como datos comparativos dicha comparación devuelve resultados lógicos.
tipo de dato: boolean Rango= true - false




